

Doris的三种表模型
Doris与其他MPP架构的数据引擎最大的区别,它天生支持3种表模式,以应对不同的应用场景。分别是:
表模式分类
- 明细模型(Duplicated Key Model)
- 主键模型(Unique Key Model)
- 聚合模型(Aggregate Key Model)
三种不同的模式对比如下:
以下是 Doris 三种核心表模型(Duplicate、Aggregate、Unique)的对比表格,总结其核心特性、适用场景及差异:
| 特性 | Duplicate 模型 | Aggregate 模型 | Unique 模型 |
|---|---|---|---|
| 存储方式 | 存储所有原始数据行,不进行任何聚合或去重,是Doris的默认表模式。 | 按聚合键(AGGREGATE KEY)自动合并数据(如 SUM/MAX/MIN 等)。 | 按主键(UNIQUE KEY)自动去重,保留最新版本数据(类似 Upsert)。 |
| 数据唯一性 | 允许完全重复的行。 | 同一聚合键的多行会被合并为一行。 | 主键相同的行会被覆盖,保证主键唯一性。 |
| 适用场景 | 需要完整明细数据的场景(如日志分析、订单流水)。 | 预聚合统计(如 PV/UV、销售额汇总)。 | 需要主键唯一性的场景(如用户表、商品表,需更新数据)。 |
| 数据更新 | 不支持更新操作,仅追加数据。 | 不支持update方式更新,但可以通过insert方式更改聚合的数据(如 SUM 累加)。 | 主键冲突时,新数据覆盖旧数据(支持 Upsert)。 |
| 查询性能 | 明细查询快,但聚合查询需实时计算,性能较低。 | 聚合查询极快(数据已预计算),但明细查询无法进行。 | 主键点查极快,范围查询效率取决于主键设计。 |
| 是否支持删除 | 支持通过 DELETE WHERE 删除数据。 | 支持通过 DELETE 语句按主键删除。 | 支持通过 DELETE 语句按主键删除。 |
| 聚合能力 | 无自动聚合,需手动写 SQL 聚合。 | 内置预聚合(如 SUM、REPLACE、MAX 等)。 | 无自动聚合,但可通过主键更新覆盖旧值。 |
| 存储空间占用 | 占用较大(存储原始明细)。 | 占用较小(数据已压缩聚合)。 | 占用中等(按主键去重,但需保留历史版本时可能较大)。 |
| 典型使用案例 | 日志流水、行为轨迹分析。 | 实时报表(如每日销售额总和、用户活跃数)。 | 用户资料表、商品库存表(需按主键更新)。 |
| 物化视图支持 | 支持,可加速聚合查询。 | 通常不需要(本身已聚合)。 | 支持,用于加速非主键列的查询。 |
| 建表示例 | DUPLICATE KEY(dt, user_id) | AGGREGATE KEY(dt, product_id) SUM(sales) | UNIQUE KEY(user_id) |
| KEY列作用 | 仅排序列,并非起到唯一标识的作用 | 兼顾 "排序列" 和 "唯一标识列",是真正意义上的 "Key 列" | 兼顾 "排序列" 和 "唯一标识列",是真正意义上的 "Key 列" |
核心差异总结
-
数据粒度
- Duplicate:保留原始明细。
- Aggregate:存储聚合后的粗粒度数据。
- Unique:存储主键粒度的最新数据。
-
写入更新
- Aggregate 通过聚合函数合并数据,Unique 通过主键覆盖更新,Duplicate 仅追加。
-
查询效率
- Aggregate 对预聚合字段查询极快,Unique 主键查询高效,Duplicate 适合复杂过滤但聚合慢。
-
适用场景
- 明细存储 → Duplicate,统计报表 → Aggregate,主键更新 → Unique。
选型建议
- 需要 100% 原始数据 → 选 Duplicate。
- 需要 预计算统计指标 → 选 Aggregate。
- 需要 按主键更新或去重 → 选 Unique。
实际操作验证
明细模型(Duplicated Key Model)
创建明细模式表时候,需要通过如下关键字指定:
DUPLICATE KEY(a,b)
例如创建一个有3个重复主键的表:
CREATE TABLE IF NOT EXISTS log_table
(
log_time DATETIME NOT NULL,
log_type INT NOT NULL,
error_code INT,
error_msg VARCHAR(1024),
_id BIGINT,
op_time DATETIME
)
DUPLICATE KEY(log_time, log_type, error_code)
DISTRIBUTED BY HASH(log_type) BUCKETS 10
PROPERTIES (
"replication_num" = "1"
);
-- 插入初始数据
INSERT INTO log_table VALUES
('2024-11-01 00:00:00', 2, 2, 'timeout', 12, '2024-11-01 01:00:00'),
('2024-11-02 00:00:00', 1, 2, 'success', 13, '2024-11-02 01:00:00'),
('2024-11-03 00:00:00', 2, 2, 'unknown', 13, '2024-11-03 01:00:00'),
('2024-11-04 00:00:00', 2, 2, 'unknown', 12, '2024-11-04 01:00:00');
查询结果如下:

再次插入重复key的数据:
INSERT INTO log_table VALUES
('2024-11-01 00:00:00', 2, 2, 'timeout', 12, '2024-11-01 01:00:00'),
('2024-11-01 00:00:00', 2, 2, 'unknown', 13, '2024-11-01 01:00:00');

从测试结果中不难发现,第二次插入数据与前面的数据,虽然有重复的key,所有结果都完全保存了。
更新数据
从下面的错误提示可知,明细表是不支持update,只有unique表支持update操作。:
learn_doris> update log_table set error_msg='success' where log_time='2024-11-01 00:00:00'
[2025-04-16 08:46:27] [HY000][1105] errCode = 2, detailMessage = Only unique table could be updated.
删除数据
明细表可以通过delete删除数据,而且可以通过duplicated key 和其他的列删除数据。
# 通过主键删除
learn_doris> delete from log_table where log_time='2024-11-01 01:00:00'
[2025-04-16 08:49:08] completed in 94 ms
# 通过非主键删除
learn_doris> delete from log_table where op_id='13'
[2025-04-16 08:49:42] completed in 77 ms
结论:明细表的crud操作,除了不能update,其他和关系型数据库类似
主键模型(Unique Key Model)
创建主键模型,需要通过如下关键字指定:
UNIQUE KEY(id)
建表:
CREATE TABLE IF NOT EXISTS user_info
(
user_id LARGEINT NOT NULL,
user_name VARCHAR(50) NOT NULL,
city VARCHAR(20),
age SMALLINT,
sex TINYINT
)
UNIQUE KEY(user_id, user_name)
DISTRIBUTED BY HASH(user_id) BUCKETS 10
PROPERTIES (
"enable_unique_key_merge_on_write" = "true", --启用写时合并
"replication_num" = "1"
);
插入数据
INSERT INTO user_info VALUES
(101, 'Tom', 'BJ', 26, 1),
(102, 'Jason', 'BJ', 27, 1),
(103, 'Juice', 'SH', 20, 2),
(104, 'Olivia', 'SZ', 22, 2);
现在数据库中的数据如下:

再次插入重复主键的数据:
-- 插入新数据,更新已有记录
INSERT INTO user_info VALUES
(101, 'Tom', 'BJ', 27, 1), -- 更新 user_id = 101 的记录
(102, 'Jason', 'SH', 28, 1); -- 更新 user_id = 102 的记录
结果如下:

从测试结果中可以看出,第二次插入的数据,覆盖了相同主键的数据。
更新数据
主键模型表,支持更新操作,但只支持更新非主键上的数据,下面是实际操作日志:
# 成功更新非主键的值
learn_doris> update user_info set age=23 where user_id=104
[2025-04-16 08:57:29] 1 row affected in 143 ms
# 更新主键的值失败
learn_doris> update user_info set user_name='Jerry' where user_id=101
[2025-04-16 08:58:36] [HY000][1105] errCode = 2, detailMessage = Only value columns of unique table could be updated
删除操作
支持通过主键和非主键delete数据:
# 通过逐渐删除数据
learn_doris> delete from user_info where user_id=104
[2025-04-16 09:02:50] 1 row affected in 111 ms
# 通过非主键删除数据
learn_doris> delete from user_info where city='BJ'
[2025-04-16 09:03:23] 1 row affected in 90 ms
结论:主键类型表,crud操作,不支持update主键外,其他与关系型数据库一致。
聚合模型(Aggregate Key Model)
创建聚合模型,需要通过如下关键字指定:
AGGREGATE KEY(dt, product_id)
与前面不同的是,除了需要指定主键外(dt,product_id),还需要指定聚合的列(sales)以及聚合规则。
完整示例:
CREATE TABLE IF NOT EXISTS user_behavior_agg
(
user_id LARGEINT NOT NULL,
load_date DATE NOT NULL,
city VARCHAR(20),
last_visit_date DATETIME REPLACE DEFAULT "1970-01-01 00:00:00", --新值替换旧值
cost BIGINT SUM DEFAULT "0", --汇总计算
max_dwell_time INT MAX DEFAULT "0" --最大值计算
)
AGGREGATE KEY(user_id, load_date, city)
DISTRIBUTED BY HASH(user_id) BUCKETS 10
PROPERTIES (
"replication_num" = "1"
);
上面的例子为例,创建了三个主键(user_id, load_date, city),同时创建了3个聚合列:
- last_visit_date:新值替换旧值
- cost:sum汇总
- max_dwell_time:取最大值
插入数据
INSERT INTO user_behavior_agg VALUES
(101, '2024-11-01', 'BJ', '2024-10-29', 10, 20),
(102, '2024-10-30', 'BJ', '2024-10-29', 20, 20),
(101, '2024-10-30', 'BJ', '2024-10-28', 5, 40),
(101, '2024-10-30', 'SH', '2024-10-29', 10, 20);

再次插入相同key的数据:
INSERT INTO user_behavior_agg VALUES
(101, '2024-11-01', 'BJ', '2024-10-30', 20, 10),
(102, '2024-11-01', 'BJ', '2024-10-30', 10, 30);

从结果中可以看到,相同key的数据直接在原有数据的基础上进行更新,而新的key数据正常插入。
更新数据
不支持更新数据:
learn_doris> update user_behavior_agg set cost=111 where user_id=102
[2025-04-16 09:15:38] [HY000][1105] errCode = 2, detailMessage = Only unique table could be updated.
删除数据
支持主键删除,不支持通过值删除:
learn_doris> delete from user_behavior_agg where cost=20
[2025-04-16 09:16:32] [HY000][1105] errCode = 2, detailMessage = delete predicate on value column only supports Unique table with merge-on-write enabled and Duplicate table, but Table[user_behavior_agg] is an Aggregate table.
learn_doris> delete from user_behavior_agg where user_id=101
[2025-04-16 09:16:35] completed in 89 ms
结论:aggregate类型表不支持更新数据,以及仅支持通过主键删除数据。
CRUD特性汇总
| 特性/表类型 | DUPLICATE 表 | UNIQUE 表 | AGGREGATE 表 |
|---|---|---|---|
| 创建 (Create) | 允许插入重复数据 | 不允许插入重复主键数据 | 允许插入重复数据,但会进行聚合 |
| 读取 (Read) | 返回所有数据,包括重复数据 | 返回唯一数据,去重 | 返回聚合后的数据 |
| 更新 (Update) | 不支持直接更新,需删除后重新插入 | 支持更新,更新时会检查主键唯一性 | 不支持直接更新,需删除后重新插入 |
| 删除 (Delete) | 支持删除,删除时会删除所有匹配行 | 支持删除,删除时会删除所有匹配行 | 支持删除,删除时会删除所有匹配行 |
| 适用场景 | 日志数据、需要保留所有历史记录的数据 | 需要唯一性约束的数据 | 需要实时聚合计算的数据 |
分区 & 分桶机制
同Hive一样,Doris也存在分区和分桶机制,而且分区和分桶的定义与hive基本一致。
- 分区:主要用来查询数据进行裁剪,将不在查询范围内的数据通过分区过滤掉。
- 分桶:在分区内部多个分桶内进行并行查询,提升查询效率。
- 表、分区、分桶的层级关系如下图所示:
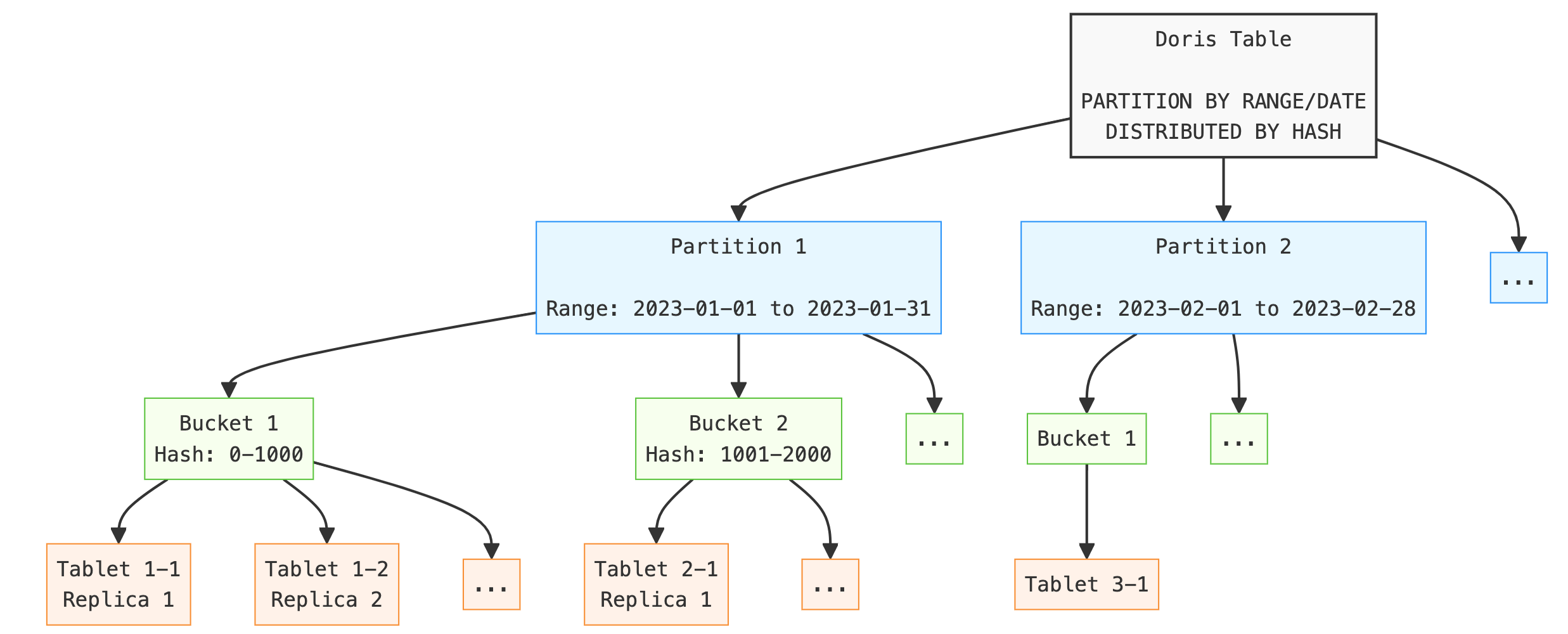
分区(Partition)
- 定义:分区是将数据按照一定维度(如时间、地域等)划分为更大的逻辑单元。
- 作用:
- 数据管理:分区可以独立管理,例如删除或移动某个分区,适合按时间管理冷热数据。
- 查询优化:通过分区裁剪(Partition Pruning),Doris 可以根据查询条件直接跳过不相关的分区,减少数据扫描范围。
- 类比:就像图书馆将图书按类别(如文学、科技、历史等)划分到不同的区域,查询时可以直接定位到相关区域,而无需搜索整个图书馆。
分区类型:
- Range 分区:根据分区列的值范围将数据行分配到对应分区
- 关键词:PARTITION BY RANGE()
CREATE TABLE orders (
order_id BIGINT,
user_id BIGINT,
product_id BIGINT,
order_date DATE,
amount DECIMAL(10, 2)
)
PARTITION BY RANGE(order_date) (
PARTITION p202301 VALUES LESS THAN ("2023-02-01"),
PARTITION p202302 VALUES LESS THAN ("2023-03-01"),
PARTITION p202303 VALUES LESS THAN ("2023-04-01")
)
DISTRIBUTED BY HASH(order_id) BUCKETS 10
properties(
"replication_num" = "1"
);
-- 插入测试数据
INSERT INTO orders (order_id, user_id, product_id, order_date, amount) VALUES
(1, 101, 201, '2023-01-15', 100.00),
(2, 102, 202, '2023-02-15', 200.00),
(3, 103, 203, '2023-03-15', 300.00);
- List 分区:根据分区列的具体值将数据行分配到对应分区。
- 关键词:PARTITION BY LIST()
CREATE TABLE products (
product_id BIGINT,
product_name VARCHAR(50),
category VARCHAR(50),
price DECIMAL(10, 2)
)
PARTITION BY LIST(category) (
PARTITION p_electronics VALUES IN ('electronics'),
PARTITION p_clothing VALUES IN ('clothing'),
PARTITION p_books VALUES IN ('books')
)
DISTRIBUTED BY HASH(product_id) BUCKETS 10
properties(
"replication_num"=1
);
INSERT INTO products (product_id, product_name, category, price) VALUES
(1, 'Smartphone', 'electronics', 500.00),
(2, 'Laptop', 'electronics', 1200.00),
(3, 'T-Shirt', 'clothing', 20.00),
(4, 'Jeans', 'clothing', 50.00),
(5, 'Novel', 'books', 15.00),
(6, 'Textbook', 'books', 100.00);
分区模式:
手动分区:用户手动创建分区
- 前面的两个例子,是用手工创建分区的方式,这里跳过。
动态分区:系统根据时间调度规则自动创建分区,但写入数据时不会按需创建分区。
动态分区具有如下特点:
- 动态分区会按照设定的规则,滚动添加、删除分区,从而实现对表分区的生命周期管理(TTL),减少数据存储压力。在日志管理,时序数据管理等场景,通常可以使用动态分区能力滚动删除过期的数据。
- 可以通过创建一个动态分区管理的表,由Doris托管该表数据的生命周期,实现改变数据的自动生命周期管理。
- 由于分区的个数是动态调整的,因此可以避免由脏数据造成的无效分区,例如:‘1970-01-01’
CREATE TABLE dynamic_orders (
order_id BIGINT, -- 订单ID,类型为BIGINT
user_id BIGINT, -- 用户ID,类型为BIGINT
product_id BIGINT, -- 产品ID,类型为BIGINT
order_date DATE, -- 订单日期,类型为DATE
amount DECIMAL(10, 2) -- 订单金额,类型为DECIMAL(10, 2)
)
PARTITION BY RANGE(order_date)() -- 按订单日期范围进行分区
DISTRIBUTED BY HASH(order_id) BUCKETS 10 -- 按订单ID的哈希值分布到10个桶中
PROPERTIES (
"dynamic_partition.enable" = "true", -- 启用动态分区
"dynamic_partition.time_unit" = "DAY", -- 动态分区的时间单位为天
"dynamic_partition.start" = "-3", -- 动态分区的起始时间为当前日期的前3天
"dynamic_partition.end" = "3", -- 动态分区的结束时间为当前日期的后3天
"dynamic_partition.prefix" = "p", -- 动态分区的前缀为 'p'
"dynamic_partition.create_history_partition" = "true", -- 允许创建历史分区
"dynamic_partition.buckets" = "10", -- 动态分区的桶数为10
"replication_num"=1 -- 副本数为1
);
上面的DDL,创建一个采用动态分区的表,含有前3天+当天+未来3天,共7个分区的数据,
假如当天的日期是2025-04-15插入合法数据:
learn_doris> INSERT INTO dynamic_orders (order_id, user_id, product_id, order_date, amount) VALUES
(1, 101, 201, '2025-04-12', 100.00),
(2, 102, 202, '2025-04-13', 200.00),
(3, 103, 203, '2025-04-14', 300.00),
(4, 104, 204, '2025-04-15', 400.00),
(5, 105, 205, '2025-04-16', 500.00),
(6, 106, 206, '2025-04-17', 600.00),
(7, 107, 207, '2025-04-18', 700.00)
[2025-04-15 00:00:10] 7 rows affected in 162 ms
插入2025-04-19分区的数据,会提示分区不存在:
learn_doris> INSERT INTO dynamic_orders (order_id, user_id, product_id, order_date, amount) VALUES
(8, 108, 208, '2025-04-19', 800.00)
[2025-04-15 00:03:20] [HY000][1105] errCode = 2,
detailMessage = Insert has filtered data in strict mode. url: http://192.168.10.3:8040/api/_load_error_log?file=__shard_6/error_log_insert_stmt_57f821333aa1434c-941b904d1428f66d_57f821333aa1434c_941b904d1428f66d
同时,当系统时间超过这个分区的数据会自动删除,引用官网的一张图来说明:
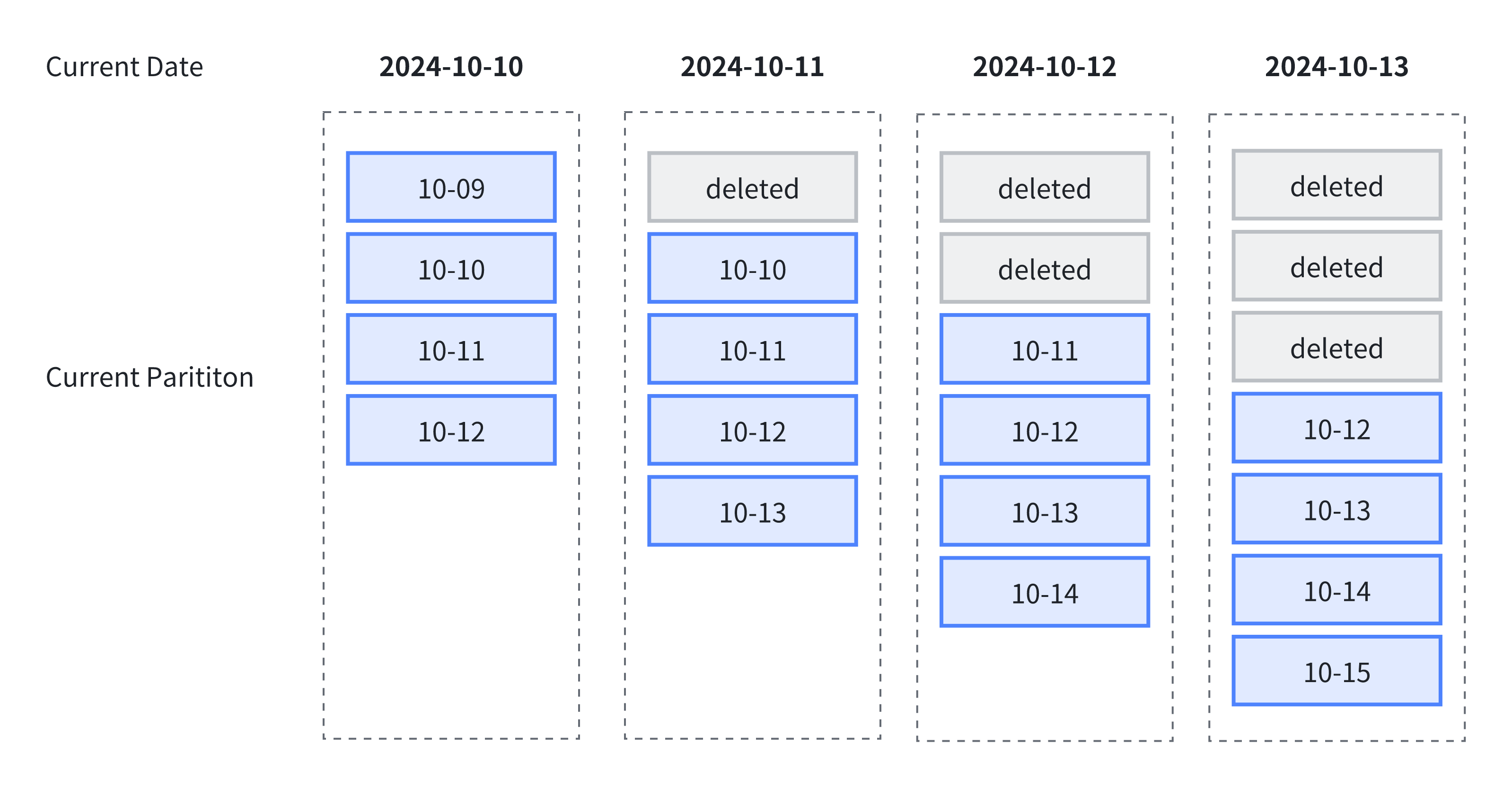
自动分区:数据写入时,系统根据需要自动创建相应的分区,使用时注意脏数据生成过多的分区。
自动分区功能主要解决了用户预期基于某列对表进行分区操作,但该列的数据分布比较零散或者难以预测,在建表或调整表结构时难以准确创建所需分区,或者分区数量过多以至于手动创建过于繁琐的问题。
- AUTO RANGE PARTITION 按范围自动分区
CREATE TABLE auto_partition_orders (
order_id BIGINT NOT NULL,
user_id BIGINT NOT NULL,
order_date DATE NOT NULL,
product_id BIGINT NOT NULL,
quantity INT NOT NULL,
price DECIMAL(10, 2) NOT NULL,
total_amount DECIMAL(10, 2) NOT NULL
)
AUTO PARTITION BY RANGE (date_trunc(`order_date`, 'day')) ()
DISTRIBUTED BY HASH(user_id) BUCKETS 10
PROPERTIES (
"replication_num" = "1"
);
-- 插入测试数据
INSERT INTO auto_partition_orders (order_id, user_id, order_date, product_id, quantity, price, total_amount) VALUES
(1, 101, '2025-04-14', 201, 2, 50.00, 100.00),
(2, 102, '2025-04-15', 202, 1, 200.00, 200.00),
(3, 103, '2025-04-16', 203, 3, 100.00, 300.00);
这时查询该表的分区,可以看到系统自动创建了3个按天的分区:

- AUTO Partition By LIst 根据列表自动分区
CREATE TABLE product_sales (
sale_id BIGINT NOT NULL, -- 销售ID,类型为BIGINT,非空
product_id BIGINT NOT NULL, -- 产品ID,类型为BIGINT,非空
product_category VARCHAR(50) NOT NULL, -- 产品类别,类型为VARCHAR(50),非空
sale_date DATE NOT NULL, -- 销售日期,类型为DATE,非空
quantity INT NOT NULL, -- 数量,类型为INT,非空
price DECIMAL(10, 2) NOT NULL, -- 单价,类型为DECIMAL(10, 2),非空
total_amount DECIMAL(10, 2) NOT NULL -- 总金额,类型为DECIMAL(10, 2),非空
)
AUTO PARTITION BY LIST (`product_category`) () -- 按产品类别进行自动分区
DISTRIBUTED BY HASH(product_id) BUCKETS 10 -- 按产品ID的哈希值分布到10个桶中
PROPERTIES (
"replication_num" = "1" -- 副本数为1
);
INSERT INTO product_sales (sale_id, product_id, product_category, sale_date, quantity, price, total_amount) VALUES
(1, 101, 'Electronics', '2025-04-14', 2, 500.00, 1000.00),
(2, 102, 'Clothing', '2025-04-15', 1, 200.00, 200.00),
(3, 103, 'Books', '2025-04-16', 3, 100.00, 300.00),
(4, 104, 'Electronics', '2025-04-14', 1, 1500.00, 1500.00),
(5, 10
同理,查看该表的分区,也已经自动创建了按照product_category建立的分区。

这里要说明的是:自动分区auto partition与动态分区 dynamic partition是可以一起使用的,即按照字段的值,根据时间自动创建分区,同时让Doris根据动态分区的设置,管理数据的生命周期。
分桶
一个分区可以根据业务需求进一步划分为多个数据分桶(bucket)。每个分桶都作为一个物理数据分片(tablet)存储。合理的分桶策略可以有效降低查询时的数据扫描量,提升查询性能并增加并发处理能力。
- Hash 分桶
- 原理:根据分桶列的值进行哈希计算,哈希值相同的数据会被分配到同一个分桶中。
- 关键词:DISTRIBUTED BY HASH() BUCKETS 10
- 适用场景:
- 业务需求频繁基于某个字段进行过滤时,可将该字段作为分桶键,利用 Hash 分桶提高查询效率。
- 当表中的数据分布较为均匀时,Hash 分桶同样是一种有效的选择。
CREATE TABLE hash_bucket_tbl (
oid BIGINT,
dt DATE,
region VARCHAR(10),
amount INT
)
DUPLICATE KEY(oid)
PARTITION BY RANGE(dt) (
PARTITION p250101 VALUES LESS THAN("2025-01-01"),
PARTITION p250102 VALUES LESS THAN("2025-01-02")
)
DISTRIBUTED BY HASH(region) BUCKETS 8;
- Random 分桶
- 原理:在每个分区中,数据随机分配到各个分桶中,不依赖于某个字段的哈希值。
- 关键词:distributed by random buckets 8
- 适用场景:
- 在任意维度分析的场景中,业务没有特别针对某一列频繁进行过滤或关联查询时,可以选择 Random 分桶。
- 当经常查询的列或组合列数据分布极其不均匀时,使用 Random 分桶可以避免数据倾斜。
CREATE TABLE orders (
order_id BIGINT NOT NULL,
user_id BIGINT NOT NULL,
order_date DATE NOT NULL,
product_id BIGINT NOT NULL,
quantity INT NOT NULL,
price DECIMAL(10, 2) NOT NULL,
total_amount DECIMAL(10, 2) NOT NULL
)
DISTRIBUTED BY RANDOM BUCKETS 8;
评论区